SPECweb2009 Release 1.20 Support Workload Design Document
The Support workload in SPECweb2009 was designed to simulate a vendor's support web site. Users are able to search for products, browse a listing of available products, filter a listing of available downloads based upon certain criteria, and then download file(s). The workload was developed by analyzing log files of actual support sites, as well as browsing major computer vendors' support sites to gather statistics such as average page size, image sizes and access frequencies (including If-Modified-Since caching from the browser side). The access patterns seen in actual log files for file downloads is modeled in this workload.
While there are dynamic pages within the support workload requested by clients, the pages are much simpler by design than the two other workloads. For example, there is no user data that must persist across page requests (and would need to be stored in a session cookie). Instead, this workload emphasizes the file downloads, which are large static files. Since there is no secure (HTTPS) component in this workload, the primary subsystems that are expected to be stressed are the network and disks.
The dynamic pages in the support workload are listed below:
index: Home page where all user sessions begin; displays product categories (i.e. servers, laptops) as hyperlinks as well as a form to search for products
catalog: Shows a list of product models (that link to the product page) within a chosen product category
search: Displays search results; form with input field for performing additional searches
product: Displays form with dropdown list boxes for selection of download category (i.e. audio drivers, BIOS updates), operating system, and language
fileCatalog: Shows a list of downloads available; each download's filename, size, and description are displayed, along with a hyperlink to download
file: Shows details about a particular download selected, including a longer description (i.e. installation instructions)
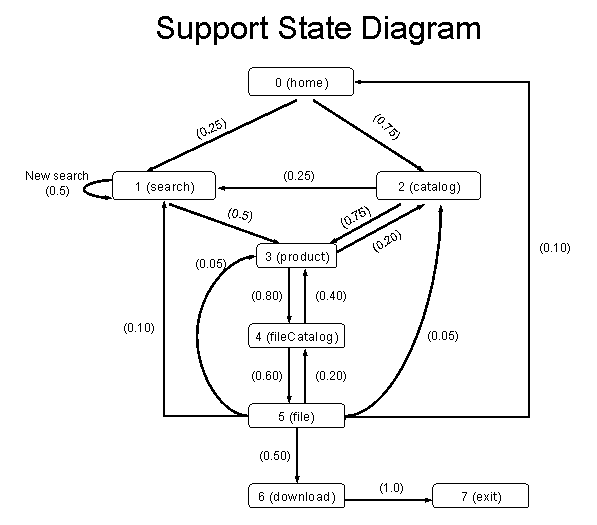
SPECweb2009 is based upon a page-based model; that is, it issues a request to a dynamic page and requests all the images that would normally exist within the page as HTML image tags. A Markov chain in the harness allows simulation of the relative page request frequencies as seen from the server side. This is represented in the prime client's SPECweb_Ecommerce.config (see the STATE_n lines). Below is a diagram of the likelihood of transitioning from one state into another:
The static portion of the Support file set is generated by Wafgen. Each workload has a fixed file set and a file set that scales with the number of simultaneous user sessions requested.
The fixed file set consists of two types of files: images that an HTML page would reference via <IMG> tags in the HTML (and that a browser would request while receiving a page response), and "padding". Padding consists of random text that is inserted at the bottom of a dynamic page to bring the file size up to what was observed with real-world E-commerce Web pages (which have, among other things, JavaScript code and numerous layout tags). The page image sizes of the fixed file set were determined by analyzing and averaging file sizes observed; the sizes range from very small (less than 100 bytes) to ~5 KB; the former are usually "spacer" images used throughout the site for aligning tables, while the latter tend to be small GIF images and Javascript includes. The page images used in the Support workload, along with their size and percentage of being cached by the browser (i.e. receiving an HTTP 304 Not Modified response from the SUT) are listed in the table below.
| File Name | Size (bytes) | 304 Request % |
| aaa | 30 | 66% |
| ccc | 30 | 66% |
| ___ | 810 | 66% |
| bar | 60 | 80% |
| blue_arrow_right | 50 | 66% |
| blue_arrow_top | 50 | 80% |
| content_action | 270 | 75% |
| content_arrow | 130 | 80% |
| 110 | 66% | |
| flattab_nl | 80 | 66% |
| flattab_nr | 90 | 66% |
| flattab_sl | 90 | 66% |
| flattab_sr | 90 | 66% |
| global | 4,180 | 80% |
| help | 700 | 66% |
| H_D | 1,830 | 66% |
| masthead_transparent | 1,510 | 80% |
| masthead_global | 110 | 66% |
| masthead_local_sep | 70 | 66% |
| masthead_subnavsep | 60 | 66% |
| nav_q | 250 | 66% |
| 360 | 66% | |
| spacer | 40 | 80% |
| template_javascripts | 5,670 | 80% |
| us | 80 | 66% |
| note | 980 | 50% |
| h_product_selection | 1,920 | 0% |
| button-1 | 240 | 0% |
| button-2 | 260 | 0% |
| button-3 | 260 | 0% |
| H_Service_Tag_Unkown | 2,170 | 0% |
Downloads are the component of the Support file set that scales as the number of requested simultaneous sessions increases. Due to the fact that larger web servers are expected to service more files, the size of the workload file set is a function of the requested number of simultaneous connections. This is to maintain some degree of reality as a some one purchasing a powerful server has greater expectations of how many downloads can be served at any given time.
The number of directories is determined using the following formula:
directory count = 0.25 * SIMULTANEOUS_SESSIONS
During a benchmark run, a Zipf distribution is used to access each directory. A Zipf distribution is a distribution where the probability of selecting the nth item is proportional to 1/n. Zipf distributions are empirically associated with situations where there are many equal-cost alternatives. The alpha value for the Zipf directory selection algorithm is 1.2; this value was chosen because experiments showed that low alpha values allow more of the file set to be cached. This workload is intended to access the disks rather than memory for a reasonable percentage of downloads.
The QoS requirements for the downloads are based on byte rates rather than the time it takes to receive the data. This approach differs from the Time_Good and Time_Tolerable metrics used for Web pages, as there is not the same expectation of large files arriving within a certain timeframe; instead, a user might expect the download to arrive at close to the bandwidth allotted by the service provider. In this benchmark, each user session is simulated at 1Mbps (100,000 bytes/second), and 95% of downloads must meet a minimum 99,000 bytes/sec rate and 99% of downloads must meet a minimum 95,000 bytes/sec for a run to be considered compliant.
Each directory consists of 16 file downloads. The downloads are grouped by file size into into six distinct categories, or classes. The classes and the distribution frequencies are shown in the table below:
Workload Class |
File sizes |
# Files per Class |
Stepping increment |
Target Mix |
Class 0 |
104,858 - 524,290 bytes |
5 |
104,858 bytes |
13.66% |
Class 1 |
629,146 - 880,804 bytes |
3 |
125,829 bytes |
12.61% |
Class 2 |
1,048,576 - 2,527,069 bytes |
4 |
492,831 bytes |
28.40% |
Class 3 |
4,194,304 - 5,546,967 bytes |
2 |
1,352,663 bytes |
22.32% |
Class 4 |
9,992,929 bytes |
1 |
N/A |
12.50% |
Class 5 |
37,748,736 bytes |
1 |
N/A |
10.51% |
Once a class has been selected, an individual file within a class is selected according to the following distribution:
Workload Class |
File number |
Target Mix |
Class 0 |
0 |
27.3% |
| 1 | 9.1% | |
| 2 | 16.5% | |
| 3 | 18.6% | |
| 4 | 28.5% | |
Class 1 |
0 | 57.9% |
| 1 | 17.8% | |
| 2 | 24.3% | |
Class 2 |
0 | 27.5% |
| 1 | 17.0% | |
| 2 | 17.0% | |
| 3 | 38.5% | |
Class 3 |
0 | 66.6% |
| 1 | 33.3% | |
Class 4 |
0 | 100% |
Class 5 |
0 | 100% |
The sizes, frequencies, and directory scaling factor were determined from aggregating server-side Web server logs and observing client-side Web browser caches.
Copyright © 2005-2010 Standard Performance Evaluation Corporation. All rights reserved.